1. 강화학습(Reinforcement Learning) 개요 및 용어
https://en.wikipedia.org/wiki/Reinforcement_learning#/media/File:Reinforcement_learning_diagram.svg

1. 심층 강화학습(Deep Reinforcement Learning) 개요
강화학습은 환경속에서 행동하며 , 시행착오로 해결책을 스스로 학습하는 것입니다.
즉, 환경속에서 어떤 행동을 해야할지를 학습하는 것을 의미합니다.
강화학습은 기본적으로 환경(Environment)/세상과, 그 세상에서 행동하는 행위자/학습자(Agent/Actor)가 존재하는 학습 방법입니다. Agent는 행동 주체로 세상/환경 속에서, 상태에 적합한 행동(Action)을 취하고, 그로 인해 환경의 상태(State)가 변화합니다. 관찰(Interpreter)을 통해 변화된 다음 상태(State)와 보상(Reward, 잘했음 못했음)을 행위자가 취한 행동에 대한 피드백을 받습니다. Agent는 이 보상을 통해 학습하여 얻은 경험을 통해 다음 행동(Action)을 결정하게 됩니다. 환경과 Agent가 이러한 상호작용으로 학습하는 것이 강화 학습입니다.
강화학습이 어려운 이유는 수많은 수학수식이나, 용어입니다. 머신러닝에서도 많은 수식이 필요하지만, 실제 사용할때는 사용자가 많은 수식을 전부 이해할 필요는 없습니다. 강화학습에는 sklearn처럼 정리되고 정형화된 라이브러리가 없습니다. 만약 DQN을 사용할 때, 몇가지 내용만 이해하면 되지만 강화학습의 교과서로 불리는 'Reinforcement Learing: An Introduction' Sutton And Barto 로 공부하면 몇백 이지를 봐야 마지막에 DQN이 나타납니다. 여러 교재를 보았지만 모든 내용을 이해할 필요는 없고, 필요한 단계만 소개된 내용은 찾을 수가 없어, 강화학습이 대중화 되기가 어려워 보입니다.
우선 용어의 개념들만 간단히 정리하고 필요할때만 찾아보는것이 좋을것 같습니다.
Reinforcement Learing: An Introduction : http://incompleteideas.net/book/the-book-2nd.html
Sutton & Barto Book: Reinforcement Learning: An Introduction
incompleteideas.net
역사적 배경
강화학습은 예전부터 연구되었으나, 본격적인 실용화는 2013년과 2015년에 발표된 딥마인드(Google DeepMind)의 연구를 통해 이루어졌습니다.
- 2013년 딥마인드의 논문' Playing Atari with Deep Reinforcement Learning '는 강화학습의 중요한 이정표를 세운 연구입니다. 이 연구에서는 심층 신경망(Deep Neural Networks)을 이용하여 Atari 게임을 학습하는 방식으로 강화학습을 적용한 최초의 중요한 사례를 다루었습니다. 특히, Deep Q-Network (DQN) 알고리즘이 처음 소개되었으며, 이 알고리즘은 강화학습과 딥러닝을 결합하여 매우 중요한 성과를 얻었습니다.
- 2015년에 발표된 논문 “Human-Level Control through Deep Reinforcement Learning”에서는 딥 Q-네트워크(DQN)를 이용하여 50여 개의 Atari 게임을 학습한 결과, 많은 게임에서 인간 수준의 성과를 능가하는 성과를 거둔 사례를 발표했습니다.
강화학습의 주요 알고리즘
- Q-Learning: 모델 프리(MDP 모델 없이) 방식으로 최적 정책을 학습하는 강화학습 알고리즘.
- Deep Q-Network (DQN): 신경망을 사용해 Q-값을 근사하는 방법.
- Policy Gradient Methods: 직접적으로 정책을 학습하는 방법.
- Actor-Critic Methods: 정책을 개선하는 Actor와 가치를 평가하는 Critic이 동시에 학습하는 방법.
2. 강화학습의 주요 요소
1) State (상태)
- 상태는 Agent가 현재 처한 상황을 설명하는 정보입니다. 이를 통해 Agent는 어떤 행동을 선택할지 결정합니다.
- State의 첫번째 글를 따서 S로 나타냅니다.
- 체스 판에서 각 말의 위치, 자율 주행 자동차의 현재 위치와 주변 환경 정보, 또는 특정 시점에서의 머신러닝 데이터셋의 모든 특성(feature) 등이 상태가 될 수 있습니다. 방탈출 게임을 할때, 방안에서 내가 관찰한 모든 힌트가 상태입니다. 힌트를 통해 어떤 행동을 할지 다음 행동을 결정합니다.
- 첫번째 상태를 $S_0$라고 하고, 첫번째 행동 후에 변화된 상태를 $S_1$, t번째 행동후에 상태를 $S_t$로 나타냅니다.
2) Action (행동)
- Agent가 특정 State에서 선택할 수 있는 모든 가능한 행동들로 Action의 머리글자를 따서 A로 표기합니다.
- t 시점의 Action은 $A_t$로 표기합니다.
- Agent는 현재 상태에서 최적의 행동을 선택하여 보상을 최대화하려고 합니다.
3) Reward (보상)
- Reward는 Agent의 행동에 대해 환경이 제공하는 피드백으로 Reward의 앞글자를 따 R로 표기합니다. 이 보상을 통해 Agent는 학습을 하고, 행동을 개선합니다. t번째 보상을 $R_t$로 표기합니다.
- 즉각적 보상과 누적 보상:
- 즉각적 보상: 행동 직후 제공되는 보상.
- 누적 보상: 장기적으로 얻을 수 있는 보상의 합입니다. 누적보상은 리턴(Return)이라고 합니다.
- 첫번째 보상부터, n번째 보상 까지 총합은 $r_t = r_0 + r_1 + r_2 ...+ r_n$
- Return은 이후에 할인율을 적용합니다. (이후 설명)
4) Agent (에이전트)
- Agent는 자신의 상태를 관찰하고, 그에 따라 행동을 선택하여 임무를 수행하는 주체입니다. 에이전트, 행위자, 학습자 등으로 부릅니다.
- 최적의 행동을 선택하여 장기적인 누적 보상을 최대화하는 것이 Agent의 목표입니다.
5) Environment (환경)
- Agent가 상호작용하는 외부 세계로, Agent의 행동에 따라 상태와 보상을 반환합니다. 강화학습을 하는 전체 환경이고, 행위자가 관찰한 정보가 상태입니다.
강화학습에서 상태, 행동, 보상의 쌍으로 표기하고, 첫번째 부터 n번째 까지 시간순서는 아래와 같이 표기됩니다.
문헌에 따라 보상(R)을 표시하는 방법이 다른데, S, A, R을 시간순서대로 표기한다는 정보만 이해하면 됩니다.


강화학습을 옛날 영화 큐브를 예로 들어 설명하면 다음과 같습니다.
- 환경(Environment): 전체 큐브 공간이 환경입니다. 큐브는 여러 개의 방으로 이루어져 있으며, 각 방에는 고유한 번호가 있습니다.
- 상태(State): 각 방에서 주어지는 정보(번호, 수식, 다른 방의 힌트 등)가 상태(State)입니다. 플레이어는 큐브 전체 구조는 알 수 없고, 각 방에 상태 정보만 알 수 있습니다.
- 행동(Action): 플레이어는 현재 상태를 기반으로 상하좌우앞뒤 중 하나를 선택하여 이동(Action)합니다.
- 보상(Reward):
- 올바른 방을 선택하면 생존하여 계속 진행할 수 있습니다.
- 목표 지점(큐브 탈출 지점)에 도달하면 + 보상이 주어집니다.
- 잘못된 방을 선택하면 함정에 빠져 - 보상(죽음)을 받습니다.
강화학습은 이렇게 상태 → 행동 → 보상을 반복하며 최적의 경로(Policy)를 학습하는 과정입니다. 처음에는 무작위로 방을 이동하지만, 학습이 진행될수록 생존 확률이 높은 경로를 더 자주 선택하게 됩니다. 이를 통해 큐브에서 탈출하는 최적의 전략을 학습하는 것이 강화학습의 핵심입니다.
3. Markov Decision Process (MDP)
Markov는 러시아 수학자인 안드레이 마르코프(Andrey Markov)의 이름에서 유래된 개념으로, 확률적 프로세스에서 시간에 따른 상태 전이의 특성을 설명하는 이론입니다. Markov Property(마르코프 성질)은 현재 상태가 미래 상태를 결정하는데 충한 정보를 제공한다는 가정입니다. 즉 미래의 상태는 현재 상태와 행동에 의존한다고 가정합니다. 마르코프 성질은 과거는 고려하지 않고, 현재 상태만으로 미래 상태를 예측할 수 있가고 가정하므로 계산이 단순해집니다. 마르코프 성질을 도하는 가장 큰 이유는 단순화로 문제를 더 쉽게 풀기 위해서입니다. MDP는 마르코프 성질을 기반으로 상태, 행동, 보상, 전이를 모델링합니다.
MDP는 강화학습에서 Agent가 환경과 상호작용하며 의사 결정을 내리는 문제를 수학적으로 모델링한 방법입니다. MDP는 다음과 같은 요소들로 구성됩니다.
1) 상태 집합 (S) : 환경의 모든 가능한 상태들의 집합입니다. 현재의 환경 상태를 나타냅니다.
2) 행동 집합 (A) : Agent가 취할 수 있는 모든 가능한 행동들의 집합입니다. 특정 상태에서 취할 수 있는 행동들을 A(s)로 표현합니다.
3) 상태 전이 확률 (State Transition Probability)
- Agent가 상태 s에서 행동 a를 취했을 때, 그 행동의 결과로 다음 상태가 s'로 전이될 확률을 나타냅니다.

상태 전이 함수 : s' = f(s,a)
4) 보상 함수 (Reward Function)
- Agent가 상태 s에서 행동 a를 취했을 때 받는 보상을 반환하는 함수입니다.
R(s,a) 또는 R(s,a, s ′ )
R(s,a) : 상태 s에서 a를 행동했을때 보상
R(s,a,s ′) : 상태 s에서 행동 a를 수행한 후 s' 에 도달했을때의 보상
5) Discount factor (할인율, γ)
- 미래 보상을 현재 보상에 얼마나 반영할지 결정하는 파라미터입니다. ()로 γ 값이 0에 가까우면 단기적인 보상이 더 중요하고, 1에 가까우면 장기적인 보상이 더 중요하게 다뤄집니다. 예를 들어 미로찾기 시 γ이 1이면, 알고리즘은 더이상 최단 경로를 찾을 필요가 없어집니다. 짧은 경로는, 먼 경로이든 Gorl에 도착했을 때 보상은 동일하기 때문입니다. 경로가 멀어질 수록 미래 보상을 discount하여서 짧은 경로에 보상을 더 주는것이 discount factor입니다.

$G_t$ 를 Return 이라고 합니다. Return은 특성 시점 t부터 미래에 걸쳐 받을 총 보상의 합을 의미합니다.
γ 이 0.9이면 R(t+1) + 0.9*R(t+2) + 0.81*R(t+3)식으로 미래의 보상일 수록 보상이 discount되기 때문에 γ를 discount factor고 합니다.
6) 가치 함수 (Value Function)
- Agent는 가치 함수를 사용하여 상태와 행동의 장기적인 중요성을 평가합니다.
- 상태 가치 함수(State-Value Function) : $V^π(S)$
- 상태 s에서 정책 π를 따를 때 얻을 수 있는 누적 보상의 기대값을 나타냅니다.
- $G_t$ : 시간 t에서의 return , 누적 보상
- : 정책
- 상태 s에서 정책 π를 따를 때 얻을 수 있는 누적 보상의 기대값을 나타냅니다.

- 행동 가치 함수 (Action-Value Function) : $Q^π(s, a)$
- 정책 상태 s에서 행동 a를 수행했을 때 받을 누적 보상의 기대값

상태 가치 함수와 행동 가치 함수는 다음의 관계를 가집니다.

7) 정책 (Policy, π)
- 정책은 Agent가 상태를 받아 행동을 반환하는 규칙입니다.
- 상태 s를 입력받아, 수행할 행동을 결정하는 함수를 정책 함수하고 하는데 두가지 형태로 나타낼 수 있습니다.
- Deterministic Policy function( 결정적 정책 함수) : a=μ(s) 특정 상태 s에서 동일한 행동 a를 반환합니다.
- Stochastic Policy Function(확률적 정책함수) : π(a∣s) 상태 s에서 행동 a를 선택할 확률을 의미합니다.
- 최적 정책 (Optimal Policy, $π^∗$) : 최적 정책(π∗)은 주어진 환경에서 누적 보상의 기대값을 최대화하는 정책입니다.
이는 최적 행동 가치 함수($Q^∗(s,a)$)에 기반해 상태 에서 항상 가장 높은 $Q^*(s, a)$를 가지는 행동 a를 선택합니다. - 탐욕정책(greedy policy)는 눈앞의 정보만으로 가장 좋아보이는 보상을 선택하는 정책입니다. 즉, 현재 상태에서 Q(s,a) 값을 기준으로 가장 높은 보상을 기대하는 행동을 선택하는 정책입니다. 탐험 없이 기대 보상이 최대인 행동을 선택합니다.
- 활용(exploitation) : 지금까지의 학습 결과를 기반으로, 현재 가장 높은 보상을 제공할 것으로 기대되는 행동(Action)을 선택하는 것입니다. 이는 일반적으로 탐욕 정책(Greedy Policy)에 따라 행동을 결정합니다.
- 탐색(exploration) : 최적 정책(Optimal Policy)을 학습하기 위해, 아직 충분히 평가되지 않았거나 새로운 행동(Action)을 시도하는 것입니다.
- 결국 강화 학습은 활용과 탐색의 균형을 어떻게 잡느냐의 문제가 중요합니다. 처음에는 랜덤하게 탐색하다가, 학습이 진행될 수록 점점 랜덤성을 줄이고 탐욕정책의 비율을 높이는 e-greedy알고리즘이 많이 사용됩니다.
최적 상태 가치 함수 : V*(S)

최적 행동 가치 함수: Q*(s,a)

최적 정책 π∗

8) 타임 스텝(time step)
타임 스텝은 에이전트(Agent)가 환경에서 행동(Action)을 수행하고, 그에 따른 보상(Reward)을 받고, 새로운 상태(State)로 전이되는 단위 시간입니다.
이는 강화학습에서 하나의 상호작용 주기를 나타내며, 에이전트가 다음 행동을 결정하기 위해 필요한 시간 간격을 의미합니다.
9) 일회성 과제와 지속성 과제(episodic task and continuous task)
일회성 과제(episodic task) : 끝이 있는 문제, 일회성 과제에서 시작부터 끝까지 일련의 시도를 에피소드(episode)라고 합니다.
지속적 과제(continuous task) : 끝이 없는 계속 지속되는 문제
3. Bellman Equations
Bellman 방정식은 최적 가치 함수와 관련된 수학적 식으로, 최적 정책을 찾는 데 사용됩니다. 이 방정식은 동적 프로그래밍(Dynamic Programming)에 기반하여 만들어졌습니다.
먼저, 동적 프로그래밍에 대해 간단히 살펴보겠습니다.
1) 동적 프로그래밍(Dynamic Programming)
동적 프로그래밍은 문제를 작은 하위 문제로 분할하고, 각 하위 문제의 결과를 테이블에 저장한 뒤, 이를 재귀적으로 활용하여 문제를 해결하는 방법입니다. 이미 해결된 하위 문제는 저장된 결과를 재사용하여 효율성을 높입니다.
동적 프로그래밍의 핵심 요소
- 최적 부분 구조 (Optimal Substructure): 문제의 최적 해가 하위 문제들의 최적 해로 구성됩니다.
- 중복되는 하위 문제 (Overlapping Subproblems): 동일한 하위 문제가 반복적으로 나타납니다.
- 메모이제이션(Memoization) 또는 테이블화(Tabulation): 하위 문제의 해를 저장하고 재사용합니다.
강화학습에서 동적 프로그래밍은 정책(Policy) π 를 최적화하는 방법론입니다.
정책 평가(Policy Evaluation), 정책 개선(Policy Improvement), 정책 반복(Policy Iteration) 또는 가치 반복(Value Iteration)을 통해 정책을 최적화합니다.
그러나 동적 프로그래밍을 적용하려면 상태 천이 확률 $ P(s'|s,a) $을 알고 있어야 하며, 상태 공간이 크면 계산량이 기하급수적으로 증가합니다. 또한, 모든 상태를 반복적으로 업데이트해야 하므로 알고리즘이 비효율적일 수 있습니다. 현실 세계에서는 상태 천이 확률을 알 수 없는 경우가 대부분이므로, 동적 프로그래밍보다는 TD 학습(Temporal Difference Learning)이나 심층 Q-러닝(Deep Q-Learning, DQL)과 같은 기법이 더 널리 사용됩니다.
DP는 벨만방정식을 반복적으로 업데이트 하는 방식으로 동작합니다.
(1) 정책 평가 (Policy Evaluation)
정책 π가 있을 때, 그 정책이 얼마나 좋은지를 평가하는 과정
가치 함수 $V^π(s)$를 벨만 방정식을 기반으로 업데이트


(2) 정책 개선 (Policy Improvement)
정책 평가로 얻은 가치 함수를 기반으로 더 나은 정책을 찾는 과정
현재 정책 π를 새로운 정책 π′로 업데이트하는 방식
현재 정책보다 더 나은 행동이 존재하면, 해당 행동을 선택하도록 정책을 수정함
새로운 정책 π′

(3) 정책 반복 (Policy Iteration)
정책 평가와 정책 개선을 번갈아 수행하여 최적 정책을 찾는 방법
수렴할 때까지 반복 실행

(4) 가치 반복 (Value Iteration)
정책 평가와 정책 개선을 동시에 수행하는 방법
가치 함수 V(s)를 바로 업데이트하며, 정책을 명시적으로 계산하지 않아도 됨


2) Bellman방정식
Bellman 방정식은 동적 프로그래밍 원리를 기반으로 개발되었으며, 초기에는 그래프의 최단 경로를 찾는 문제에 활용되었습니다.
예를 들어, 출발점에서 특정 노드 v까지의 최단 거리를 찾는 문제를 생각해보겠습니다.
이 경우, d(v)는 다음과 같은 방식으로 업데이트됩니다:

여기서 d(u)는 출발점에서 u까지의 거리, $d_{uv}$는 u에서 v까지의 거리입니다. 이 식을 통해, 이미 알고 있는 거리와 새로운 경로를 비교하여 최단 거리를 갱신할 수 있습니다.
강화 학습에서는 Bellman 방정식을 활용하여 특정 시점까지의 총 보상을 계산합니다. 구체적으로, 현재 상태 s에서 행동 a를 선택했을 때의 보상과 다음 상태 s′에서의 최대 누적 보상을 더하여 최적 행동을 결정합니다. 이 과정을 통해 최대 누적 보상을 점진적으로 업데이트합니다.
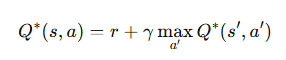
벨만 방정식을 아래와 같이 복잡하게 표시하기도 한데, 기본적인 개념은 위의 공식을 이해하면 충분합니다.
강화 학습에서 누적 보상 G는 다음과 같이 정의 됩니다.

이를 t시점의 누적 보상으로 동적방정식으로 재귀적으로 일반화 하면 다음과 같습니다.

최적 행동 가치 함수 Q*(s,a)는 상태 s에서 행동 a를 했을 때 기대 누적 보상을 나타내므로, 다음과 같이 나타낼 수 있습니다.
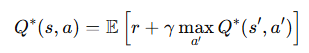
Bellman 방정식은 누적 보상 GG를 동적 프로그래밍으로 재귀적으로 표현한 식에서 유도된 것입니다. 이를 통해 강화학습에서 최적 정책을 점진적으로 학습할 수 있는 기반을 제공합니다.
강화학습의 근간인 Q알고리즘이 벨만 방정식을 기초로하여, 재귀적으로 정책을 업데이터해 나갑니다.
Q알고리즘은 이후 별도 설명합니다.

벨만 방정식을 반복적으로 업데이트 하는데 이를 TD학습의 반복적 업데이트라고 합니다.
Q러닝은 환경 모델이 없어도 작동하는 모델 프리(Model-Free)알고리즘으로 Agent가 환경과의 상호작용으로 학습합니다.
수식을 복잡하게 써서 아래와 같이 표시하기도 합니다.
아래는 전이 확률과 보상함수를 알아야 작동하는 모델 기반 (Model-Based) 알고리즘에서 사용되는 수식입니다.
상태 가치 함수의 벨반 방정식

행동 가치 함수의 벨만 방정식

4. 몬테카를로(Monte Carlo)방법
몬테카를로 기법은 무작위 샘플링(Random Sampling)을 이용하여 근사적인 해를 구하는 수치적인 기법입니다.
쉽게 설명하면, 특정 지역의 여행 지도를 만들고 싶다고 가정해보겠습니다. 해당 지역을 여행하는 1000명의 이동 데이터를 무작위로 수집하여 지도에 표시하면, 여행자들이 자주 방문하는 장소와 이동 경로를 분석할 수 있습니다. 즉, 여러 번 시행할수록 중요한 정보(주요 관광지, 최적 경로)가 점점 더 많이 누적되고, 이를 활용하면 실제 여행 경로 정보를 근사적으로 예측할 수 있습니다.
이처럼, 몬테카를로 기법은 무작위 데이터를 기반으로 반복 시행을 수행하여 점진적으로 정확한 해를 도출하는 방식으로 활용됩니다.
강화학습에서 MC방법은 에피소드가 종료된 후 Return을 계산하여, 가치함수를 업데이트 하는 방법입니다.
수렴속도가 느리고, 에피소트가 끝나야 업데이트가 가능해서 이후 TD나 DQN등으로 발전되었습니다.
MC 방법은 최적 정책을 학습하는 과정이고, 에피소드가 끝날때 마다 정책 평가를 수행하고, 반복 과정에서 정책 개선을 주기적으로 수행하는 방법 정도로만 이해하면 충분할 것 같습니다.




5. On-policy 와 Off-policy
On-policy와 Off-policy는 강화학습에서 경험 데이터를 어떻게 활용하여 정책을 학습하는지를 나타내는 개념입니다.
온-정책(on-policy) : 스스로 쌓은 경험을 토대로 자신의 정책을 개선하는 방식입니다. 환경에서 행동을 하면 그에대한 상태와 보상을 받으면서 학습하는 방식입니다.

오프-정책(off-policy) : 자신과 다른 환경에서 얻은 경험을 토대로 자신의 정책을 개선하는 방식입니다. 이미 저장된 다른 환경에서의 상태, 행동, 보상을 학습하는 방식입니다.
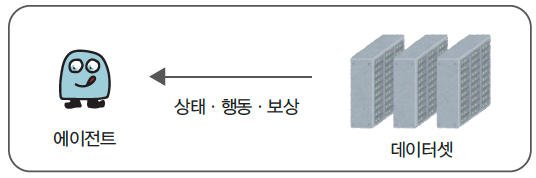
6. TD 학습(Temporal Difference)
Temporal Difference(시간 차이): TD 학습은 시간 단계별로 상태 가치 또는 행동 가치 함수의 값을 예측하고, 이를 기반으로 업데이트합니다. 현재 상태에서 얻은 보상과 다음 상태의 가치 함수를 기반으로 예측 오류를 계산하고, 이를 이용해 가치 함수를 점진적으로 개하는 방식입니다.
MC 학습처럼 에피소드가 종료될 때까지 기다릴 필요 없이, 매 단계마다 가치 함수를 업데이트합니다.
TD법에 크게 SARSA (State-Action-Reward-State-Action)와 Q-Learning 알고리즘이 있습니다.
SARSA는 주로 On-policy 그리고 Q-Learning에서는 Off-policy를 사용합니다.
2개의 차이는 SARSA는 Bellman 기대 방정식(Expected Bellman Equation)을 사용하고, Q-Learning에서는 Bellman 최적 방정식(Optimal Bellman Equation)을 사용합니다.
아래는 Q-Learning과 SARSA 알고리즘의 설명입니다.




Q-Learning과 SARSA의 차이가 이해되지 않아 GTP에 여러번 물어본 결과, SARSA는 실제 다음 action을 가지고, Q함수를 업데이트 한다는 점으로 보입니다. (GTP가 틀릴수도 있습니다)
아래 코드 상 SARSA는 random으로 선택된 next_action이 Q함수에 업데이트 될 수 있는 점이 차이로 보입니다.
이 특성으로 SARSA는 더 안정적이고, Q-Learning은 최적 정책에 좀 더 빨리 수렴이 가능합니다.

7. Model based 와 Model Free
강화 학습에서 환경과의 상호작용 방식에 따라 모델 기반(Model-based)과 모델 프리(Model-Free)방법으로 나뉩니다.
용어정도만 이해하면 될것 같습니다.
모델학습이란 상태 전이 확률 P(s'|s,a) 과 보상함수 R(s,a)를 학습하는 것을 말합니다.
즉 모델은 강화학습에서 환경이 어떻게 동작하는지 예측하는 기능을 의미합니다.
Model Base란 모델 학습으로 상태 천이 확률과 보상함수를 알고 있다고 가정하여 정책을 최적화 하는 방법입니다.
효율적인 정책 탐색이 가능하고, 빠르게 학습이 가능하지만 모델이 부정확하면 성능이 떨어질 수 있습니다.
모델 프리는 상태 전이 확률이나, 보상 함수 정보를 사용하지 않고 직접 경험을 통해 최적 정책을 학습하는 방식입니다.
모델 프리도 Value-based와 Policy-based로 나뉩니다.
| Value-based | 환경과 상호작용하며 상태-가치 함수를 학습하여 최적 행동을 결정 | Q-Learning DQN |
| Policy-based | 정책 자체를 직접 학습하여 최적 행동을 찾음 | REINFORCE PPO (목적함수에 제약을 추가) TRPO |
| Value+Policy Hybrid | 정책 기반 + 가치 기반 방법을 결합한 방법 | A2C (분산학습 알고리즘) DDPG(결정적 정책을 따르는 알고리즘) SAG |
심층 강화학습 알고리즘의 종류는 모델 기반 여부에 따라 아래와 같이 분류됩니다.

참조(REFERENCE) : 이미지 및 알고리즘
Reinforcement Learning: An Introduction - Richard S. Sutton and Andrew G. Barto
- http://incompleteideas.net/book/RLbook2020.pdf
Machine Learning - Tom M. Mitchell
- http://www.cs.cmu.edu/~tom/files/MachineLearningTomMitchell.pdf
Deep Learning from scratch 4 (밑바닥부터 시작하는 딥러닝4 Koki Saitoh)
- https://github.com/WegraLee/deep-learning-from-scratch-4