개별 변수, 변수간 상관관계를 분석하고 비지니스 가설을 수립하는 단계이다.
탐색적 데이터 분석 단계를 개인적으로 정형화 하는편이 좋은것 같다.
개인적으로 아래와 같이 절차로 확인
1. 프로파일링
2. 변수종류
3. 기초 통계 확인
4. 중복데이터 처리
5. 결측치 처리
6. 이상치 처리
7. 변수간 상관관계 분석
8. 범주형 변수변환
| 1. 프로파일링 | ProfileReport | import pandas_profiling pandas_profiling.ProfileReport(df) 판단스에서 제공하는 프로파일링으로, 전체적인 EDA를 한번에 확인 할 수있다. 리포트를 확인하고, 어떤 항목을 EDA할지 판단할 수 있다. |
| 2. 변수종류 | df.info() | 연속형 변수, 범주형 변수 및 결측치 확인 |
| 3. 기초 통계 확인 | df.describe(include='all') | 평균, min, max등으로 이상치 여부, 범주형 변수 개수 확인 |
| 4. 중복데이터 처리 | df[df.duplicated()] | 중복 데이터를 확인한다. 중복으로 판단되면 df.drop_duplicates() 로 중복을 제거한다. |
| 5. 결측치 처리 | dropna() SimpleImputer KnnImputer |
결측치 처리방법 1.단순대치법 1) 완전분석법 : 결측치 제거 2) 평균대치법 - 비조건부평균대치법 : 평균으로 대치 - 조건부 평균대치법 : Regression으로 대치 3) 단순확률 대치법 : 표준편차의 과소추정을 해결한 방법으로 KNN대치법이 있다. 2.다중대치법 |
| 6. 이상치 처리 | ESD 방식 IQR 방식 |
시각화는 boxplot으로 확인 ESD방식 : 평균에서 3표준편차 밖의 값 mean() - 3*std(), mean() + 3*std() IQR방식 : 사분위수를 이용한 방식 (IQR : Q3-Q1) 1) Turky : Q1-1.5*IQR, Q3+1.5*IQR 2) Carling : Q2 -2.3*IQR, Q2+2.3*IQR |
| 7. 변수 변환과 상관관계 분석 | 더비변수 파생변수 생성 |
1. 프로파일링
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
df = sns.load_dataset('titanic')
df.head()
import pandas_profiling
pandas_profiling.ProfileReport(df)프로파일링으로 전체적인 EDA 결과를 확인한다.
Overview
첫번째 확인해야할 내용은
숫차형 변수 11개, 범주형 변수 6개가 있고,
결측치는 181개로 전체 1.8%
중복값은 56개로 전체 6.3%이다.

두번째는 Alerts를 확인해야하는데, EDA를 어떤것이 필요한지를 추가적으로 확인할 수 있다.
survived는 sex와 강한 상관관계가 있고, pclass와 class, embarked와 embark_town, adalt_male과 survived 등이상관관계가 있는것을 확인 할 수 있다.
sibsp와 parch는 결측치가 68%와 76%로 column을 제거하는것이 좋을것 같다.

이후 변수별로 리포트를 꼼꼼하게 확인 후 분석이 필요하다.
변수간 상관관계 중복값, heatmap정보등 여러가지 정보를 확인 할 수 있다.
큰데이터셋의 경우 시간도 오래 걸리고 메모리등의 이슈로 profile report를 없는 경우가 많다.
2. 변수관계 확인
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 11 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 survived 891 non-null int64
1 pclass 891 non-null int64
2 sex 891 non-null object
3 age 714 non-null float64
4 sibsp 891 non-null int64
5 parch 891 non-null int64
6 fare 891 non-null float64
7 embarked 889 non-null object
8 class 891 non-null object
9 adult_male 891 non-null bool
10 embark_town 889 non-null object
dtypes: bool(1), float64(2), int64(4), object(4)
memory usage: 70.6+ KB총 데이터셋은 891개이고
범주형변수가 5개, 연속형변수가 6개가 있다.
age와 sipsp, parch, fare embark, embark_town은 결측치있어 처리가 필요하다.
3. 기초 통계확인
df.describe(include='all')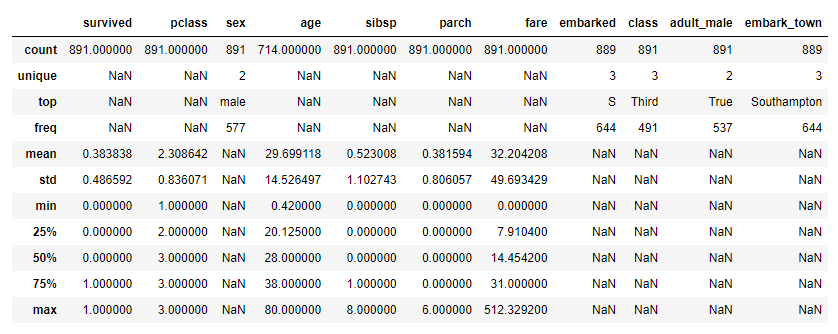
전체적인 기초 통계량 확인한다.
수치형 변수의 이상값으로 의심되는 부분은 fare의 최대값이 다른구간대비 매우 커보이지만 부유층의 요금이라고 생각한다면 특별히 이상값은 없어보이고, 명목혀 변수들은 종류가 최대 3개정도로 dummy처리가 필요해보인다.
4. 중복 확인
df[df.duplicated()]
고유값이 없고, 카테로리 내용으로 중복으로 간주하기 어려워 중복 항목 제거는 불필요한것으로 판단된다.
5. 결측값 확인
결측값의 시각화 : age, embarked, embark_town에 결측값이 있다. deck은 결측값이 많으므로 우선 컬럼 제거한다.
sns.heatmap(df.isnull())
# age에 177개 결측값, embarked와 embark_town에 각각 2개의 결측치가 있다.
df.isna().sum()
survived 0
pclass 0
sex 0
age 177
sibsp 0
parch 0
fare 0
embarked 2
class 0
adult_male 0
embark_town 2
# embarked와 embark_town확인
df.embark_town.value_counts()
Southampton 644
Cherbourg 168
Queenstown 77
df.embarked.value_counts()
S 644
C 168
Q 77
# 2개는 명목형 변수로 단순 대치법으로 최빈값으로 대치한다.
from sklearn.impute import SimpleImputer
simple = SimpleImputer(strategy='most_frequent')
col = ['embarked','embark_town']
df[col] = simple.fit_transform(df[col])
df.isna().sum()
survived 0
pclass 0
sex 0
age 177
sibsp 0
parch 0
fare 0
embarked 0
class 0
adult_male 0
embark_town 0
# age는 결측값이 많지만, drop하기에는 영향이 커보인다.
# 평균으로 대치하는 것보다, Nearest Neighbor로 값을 대치한다.
from sklearn.impute import KNNImputer
col = df.select_dtypes(include=np.number).columns
df[col] = KNNImputer(n_neighbors=5).fit_transform(df[col])
df.isna().sum()
survived 0
pclass 0
sex 0
age 0
sibsp 0
parch 0
fare 0
embarked 0
class 0
adult_male 0
embark_town 0
6. 이상치 확인
시각화는 box plot을 주로 이용한다.
sns.boxplot(data=df)
age와 Fare를 좀더 상세하게 확인
sns.boxplot(df, x='age')
sns.boxplot(df, x='fare')
이상치로 나이는 80세로 이상치로 판단하기는 여럽고, 요금은 IQR로 추가로 실체 데이터를 확인해본다.
def get_outlier( x:pd.Series ):
q1, q3 = x.quantile([0.25,0.75])
iqr = q3-q1
return (x < (q1 - 1.5*iqr)) | (x > (q3 + 1.5*iqr))
df[get_outlier(df.fare)].sort_values(by="fare", ascending=False)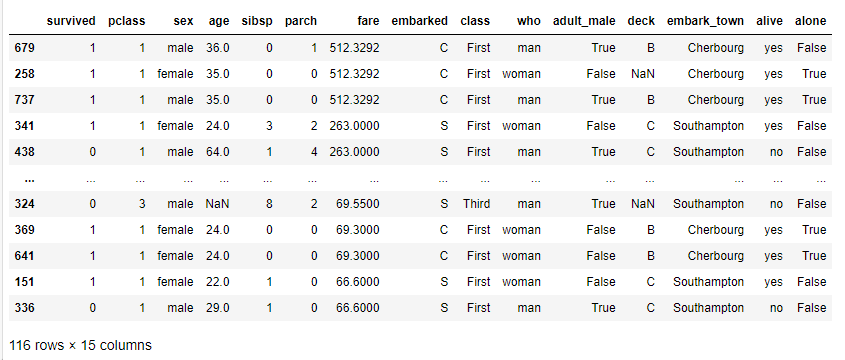
Frist클래스 승객으로, 비싼 요금을 지불할 수 있을것으로 보여 이상치로는 판단되지는 않아 이상치 처리는 하지 않는다.
이상치로 판단되면 제거하거나 대치를 한다.
7. 변수 변환과 상관관계 분석
가변수나, 상관관계 분석, 파생변수, 주성분 분석등 변수간의 관계를 탐색한다.
1차로 가변수 처리부터 진행한다.
df.describe(include=object)

명목형 변수가 2개 ~ 3개로 상관분석 전 가변수화 부터 진행한다.
명목형 변수의 개수가 많으면 변수 생성이 많아져 다른 방법을 사용해야한다.
embark와 embark_town은 내용이 동일하여 둘중하나는 삭제한다.
boolean도 0과 1로 변환한다.
df = pd.get_dummies(df, drop_first=True)
df.drop(columns=['embarked_Q','embarked_S'], inplace=True)
df.select_dtypes(include=bool).columns
df.head()
상관관계를 확인해보자
plt.figure(figsize=(9,9))
sns.heatmap(df.corr().abs(), annot=True)
plt.show()
alive_yes와 survived는 동일하고, adult_male과 who_man 'class_Third','class_Second'도 동일하다. 동일한 변수는 삭제한다.
'전처리' 카테고리의 다른 글
| Sklearn Featureselection방법들 (0) | 2023.12.28 |
|---|---|
| itertools [변수선택, 유용한 함수] (0) | 2023.10.18 |
| feature_selection (변수 선택 법) (0) | 2023.08.03 |
| Seaborn (0) | 2023.08.01 |
| 시계열 데이터 (0) | 2023.07.07 |