
Pandas에서 가장 강력한 기능으로 groupby를 들 수 있다.
pivot_table, crosstab, melt등의 함수를 모르더라고 groupby의 원리만 이해한다면 groupby를 통해 실행할 수 있다.
groupby의 동작이 pandas 버전에 따라 달라지므로, 우선 ADP시험장 버전으로 설명한다.(Pandas버전에 따라 동작이 달라질 수 있음)
아래는 groupby함수이고, 실행결과는 groupby객체가 반환된다.
| DataFrame.groupby(by=None, axis=<no_default>, level=None, as_index=True, sort=True, group_keys=True, observed=<no_default>, dropna=True) |
Groupby의 동작원리를 이해하기 위해 가장 간단한 데이터 프레임을 생성한다.
C0, C1, C2 3개의 컬럼을 가지고 C0가 명목형데이터로 C0로 groupby를 수행한다.
import pandas as pd
import numpy as np
df = pd.DataFrame({'C0': ['A', 'B', 'C', 'A', 'B'],
'C1': [1, 2, 3, 4, 5],
'C2': [100, 150, 200, 250, 300]})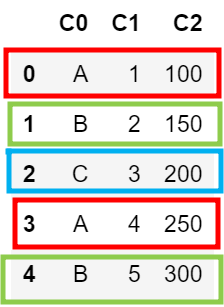
데이터 프레임에 A가 0,3 번째, B가 1,4번째 C가 2번째에 위치하고 있다.
Groupby를 C0로 실행 시 A, B, C의 3개의 그룹을 생성하고 집계함수를 수행한다.
아래는 일반적인 groupby를 실행했을 때의 결과이다.
1. Groupby 집계함수
df.groupby(by='C0').mean()
결과를 보면 groupby의 by 인자가 key로 되고 다른 컬럼들의 mean()으로 집계 결과가 value로 집계된다.
여기서 이해해야할 부분은 출력결과는 집계함수가 수행되어 원본 데이터프레임 크기보다 작아진다.
2. Groupby 객체
동작원리는 이해하기 위해 groupby 객체를 retrun받아 객체가 어떻게 구성되는지 확인해보자.
아래 코드는 groupby객체를 grp로 전달받았다.
grp는 이터레이터(반복)객체로 for 반복 시 by인자의 key와 A, B, C 3개의 객체로 이루어짐을 확인할 수 있다.
grp = df.groupby('C0')
for key, g in grp:
display(key, g)
display(g.mean(numeric_only=True))
결과를 출력해보면 by인자로 key가 전달되고, A에 해당되는 데이터프레임, B에 해당되는 데이터프레임, C에 해당되는 데이터프레임 3개로 출력됨을 볼 수 있다.
df.lioc[ df['C'] == 'A'], df.lioc[ df['C'] == 'B'], , df.lioc[ df['C'] == 'C'] 의 결과처럼 group내부적으로 동작함을 알 수 있다.
결국 각각의 그룹의 데이터 프레임을 집계후 이 결과들을 합쳐주는 결과로 동작하게 된다.
3. apply
groupby이후 apply함수로 데이터를 처리할 수 있다.
일반적으로 apply는 axis=0(컬럼), axis=(행)단위로 처리를 수행하지만 groupby로 수행할 경우 위에서 작성한 데이터 프레임을 전달받게된다.
df.groupby('C0').apply(lambda x: pd.Series({'type':type(x),'C1 mean':x['C1'].mean(),'C2 mean':x['C2'].mean()}))

groupby의 apply함수 내 전달받은 객체를 확인하기 위해 type(x)로 출력하고, C1의 평균과 , C2의 평균을 출력하는 코드이다. agg를 사용하여 여러개로 출력하지 않아도 apply에서 pd.Series로 return하면 pd.Series로 합쳐서 1개의 데이터 프레임으로 합쳐서 전달함을 알 수 있다. 여기서 index는 group의 key로 동작한다.
만약 apply에 데이터프레임으로 출력하면 어떻게 동작할까?
df.groupby('C0').apply(lambda x: pd.DataFrame({'type':type(x),'mean':[x['C1'].mean(),x['C2'].mean()]}))
결과를 보면 데이터프레임을 concat으로 합치고, groupby의 key가 앞에 붙어서 multi-index형태로 출력됨을 볼 수 있다.
결국 apply결과를 합쳐 보여줌을 알 수 있다.
여기서, groupby키를 없앨수도 있는데 groupby인자인 group_keys를 False하면 결과에 출력되지 않는다.
(이것도 Pandas 버전에 따라 인자가 동작하지 않는 경우도 있다)
결국 집계를 위해서는 pd.Series로 반환하면 되는데, 아래와 같은 경우 DataFrame으로 return하면 편리하다.
만약, StandardScaler scale을 각각의 그룹별로 수행 후 이를 합치고 싶을 경우의 코드 에제이다.
from sklearn.preprocessing import StandardScaler
col = ['C1','C2']
df.groupby('C0').apply(lambda x: pd.DataFrame(StandardScaler().fit_transform(x[col]), columns=col, index=x.index))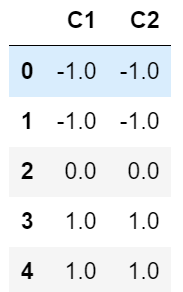
apply함수로 반환시 원본 데이터 프레임과 같을 경우, key가 업어지고, index순서도 원본 index순서와 같아진다.
이때 index에 x.index를 사용해야 원본과 같은 결과가 출력된다.
(Pandas 버전에 따라 groupkye가 붙을 수 있다. 이경우 group_keys=False로 수행하면 된다)
아래는 group_keys=True시 결과이다.
from sklearn.preprocessing import StandardScaler
col = ['C1','C2']
df.groupby('C0', group_keys=True).apply(lambda x: pd.DataFrame(StandardScaler().fit_transform(x[col]), columns=col, index=x.index))
4. Transform
만약 각 column별로 수행하는 방법을 하려면 어떻게 해야할까?
apply로 수행 후 각 column별로 수행하면 되지만, 원본전체 행단위로 수행하고 원본과 같은 크기 전체를 전달받고 싶은 경우 groupby후 transform을 사용할 수 있다.
즉, transform의 결과는 원본데이터와 동일해야한다.
아래는 C1과 C2의 그룹평균으로 새로운 컬럼으로 생성하는 예제이다.
from sklearn.preprocessing import StandardScaler
col = ['C1','C2']
df[['C1_Mean','C2_mean']] = df.groupby('C0')[col].transform(np.mean)
df
transform의 결과는 집계된 결과(원본보다 작아짐)이 아니라 각 index별 결과를 return함을 알 수 있다.
A, B, C 별 C1과 C2의 컬럼값이 return되는것을 확인 할 수 있다.
transform이 유용한 경우는 , 아래와 같은 경우이다.
A,B,C 그룹별로 C1과 C2의 결측치를 각 그룹별 평균값으로 대치한다.
df[col] = df.groupby('C0')[col].transform(lambda x: x.fillna(x.mean()))
* 데이터 전처리 시 가장 강력한 도구인 groupby 의 동작원리는 이해한다면 APD등 시험의 가장 까다로운 전처리에 유용하게 사용할 수 있다.
'전처리' 카테고리의 다른 글
| 이상치 탐색 (1) | 2024.06.08 |
|---|---|
| 변수선택법 - SelectKBest (0) | 2024.05.15 |
| ColumnTransformer (0) | 2024.04.20 |
| Sklearn Featureselection방법들 (0) | 2023.12.28 |
| itertools [변수선택, 유용한 함수] (0) | 2023.10.18 |