
Sklearn과 Seaborn 라이브러리에 load_csv등으로 불러오지 않고 라이브러리 내 dataset함수를 호출하는 방법이 있다.
1. Sklearn.datasets
sklearn에 datasets 에는 3가지 종류가 잇다.
1. load_xxx : 내장데이터셋
2. make_xxx : 확률분포로 가상의 데이터셋 생성
3. fetch_xxx : 크기가 큰 데이터셋 다운로드
| dataset | 종류 | |
| load_iris | 붓꽃데이터 (IRIS) 종류 분류 | 분류 |
| load_diabetes | 당뇨병환자 데이터 | 회귀 |
| load_digits | 숫자 이미지 데이터 (0-9) | 분류 |
| load_linnerud | 운동능력데이터 | 회귀 |
| load_wine | 와인등급데이터 | 분류 |
| load_brest_cancer | 유방암진단 | 회귀 |
아래는 가장 많이 사용하는 iris 데이터 load방법이다.
대부분 iris.data로 X값들이고, y는 iris.target등으로 가져올수있다. (방식은 동일)
import pandas as pd
from sklearn.datasets import load_iris
iris = load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
df["target"] = iris.target
df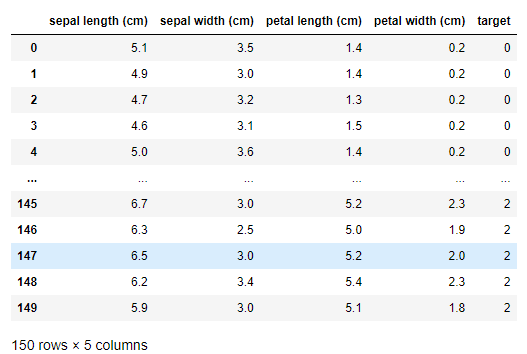
load_xxx로 dataset을 불러오면 일종의 dictionary형태의 자료형태를 가지고 있다.
from sklearn.datasets import load_iris
iris_data = load_iris()
keys = iris_data.keys()
keysdict_keys(['data', 'target', 'frame', 'target_names', 'DESCR', 'feature_names', 'filename', 'data_module'])- data : 피처의 데이터 세트
- target : 종속변수의 값.
- target_names : 종속변수의 개별 레이블의 이름.
- feature_names : 피처의 이름, 독립변수의 이름.
- DESCR은 데이터 세트에 대한 설명과 각 피처의 설명.
2. seaborn datasets
df = sns.load_dataset('titanic')
df.head()seaborn은 load_dataset과 데이터셋 이름으로 데이터를 load할 수있다.
데이터셋을 다운받기때문에 네트워크가 연결되어있어야한다.
내장데이터셋은 아래 명령어로 가져올 수 있다.
sns.get_dataset_names()
['anagrams',
'anscombe',
'attention',
'brain_networks',
'car_crashes',
'diamonds',
'dots',
'dowjones',
'exercise',
'flights',
'fmri',
'geyser',
'glue',
'healthexp',
'iris',
'mpg',
'penguins',
'planets',
'seaice',
'taxis',
'tips',
'titanic']'전처리' 카테고리의 다른 글
| Pandas groupby secton4 transform (0) | 2023.06.20 |
|---|---|
| Pandas groupby section3 (agg) (0) | 2023.06.20 |
| Pandas groupby section2(Multi Key) (0) | 2023.06.20 |
| Pandas groupby section1 (0) | 2023.06.20 |
| jupyter notebook (0) | 2023.06.14 |